

В этом параграфе мы посмотрим на, казалось бы, те же самые модели машинного обучения с другой стороны, проинтерпретировав их, как вероятностные. В первом разделе мы расскажем, как обращаться с вероятностными моделями, и покажем, что привычный вам подбор параметров модели с помощью минимизации функции потерь соответствует их подбору методом максимального правдоподобия, что даст возможность транслировать в мир ML известные результаты о свойствах оценок максимального правдоподобия, но в то же время и обнажит их недостатки. Это позволит нам по-новому взглянуть на логистическую регрессию и с новым пониманием сформулировать её обобщение – generalized linear model (GLM). По ходу дела выяснится, что большинство классификаторов, хоть и делают вид, что предсказывают корректные вероятности, на самом деле вводят в заблуждение, и в третьем разделе мы поговорим о том, как проверить отклонение предсказанных значений от истинных вероятностей и как поправить ситуацию. Далее, мы обсудим генеративный подход к классификации и разберём несколько примеров генеративных моделей, после чего перейдём к байесовскому подходу оценивания параметров, который, хоть зачастую и трудно осуществим вычислительно, однако обладает большей теоретической стройностью, позволяет оценивать распределение параметров и предсказаний – то есть, например, уверенность в нашей оценке – а, кроме того, дает нам возможность измерить качество модели, не прибегая к проверке на тестовой выборке.
Случайность как источник несовершенства модели
Практически любая модель, которую мы строим, несовершенна. Но объяснять это несовершенство можно по-разному.
Представим, что мы решаем задачу регрессии $y\simeq \langle x, w\rangle$: например, пытаемся по университетским оценкам выпускника предсказать его годовую зарплату. Ясно, что точная зависимость у нас не получится как минимум потому, что мы многого не знаем о выпускнике: куда он пошёл работать, насколько он усерден, как у него с soft skills и так далее – как же нам быть?
Первый вариант – просто признать, что мы не получим идеальную модель, но постараться выучить насколько это возможно оптимальную, то есть приблизить таргет предсказаниями наилучшим образом с точки зрения какой-то меры близости, которую мы подберём из экспертных соображений. Так мы получаем простой инженерный подход к машинному обучению: есть формула, в которой присутствуют некоторые параметры ($w$), есть формализация того, что такое «приблизить» (функция потерь) – и мы бодро решаем задачу оптимизации по параметрам.
Второй вариант – свалить вину за неточности наших предсказаний на случайность. В самом деле: если мы что-то не можем измерить, то для нас это всё равно что случайный фактор. В постановке задачи мы заменяем приближённое равенство $y\simeq \langle x, w\rangle$ на точное
$$y = \left(\langle x, w\rangle, \mbox{искажённое шумом $\varepsilon$}\right)$$
Например, это может быть аддитивный шум (чаще всего так и делают):
$$y = \langle x, w\rangle + \varepsilon$$
где $\varepsilon$ – некоторая случайная величина, которая представляет этот самый случайный шум. Тогда получается, что для каждого конкретного объекта $x_i$ соответствующий ему истинный таргет – это сумма $\langle x_i, w\rangle$ и конкретной реализации шума $\varepsilon$.
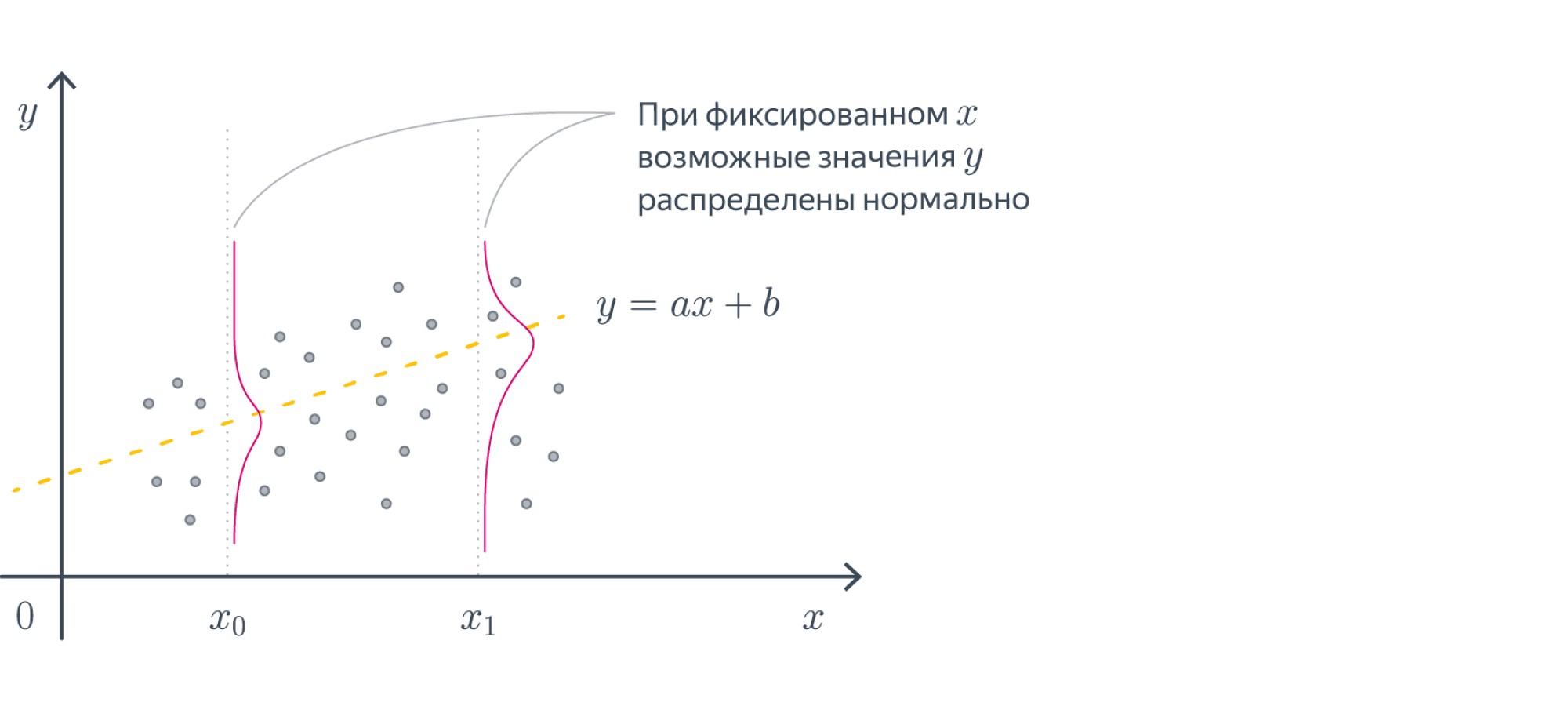
При построении такой модели мы можем выбирать различные распределения шума, кодируя тем самым, какой может быть ошибка. Чаще всего выбирают гауссовский шум: $\varepsilon\sim\mathcal{N}(0,\sigma^2)$ с некоторой фиксированной дисперсией $\sigma^2$ – но могут быть и другие варианты.
Проиллюстрируем, как ведут себя данные, подчиняющиеся закону $y = ax + b + \varepsilon$, $\varepsilon\sim\mathcal{N}(0, \sigma^2)$:
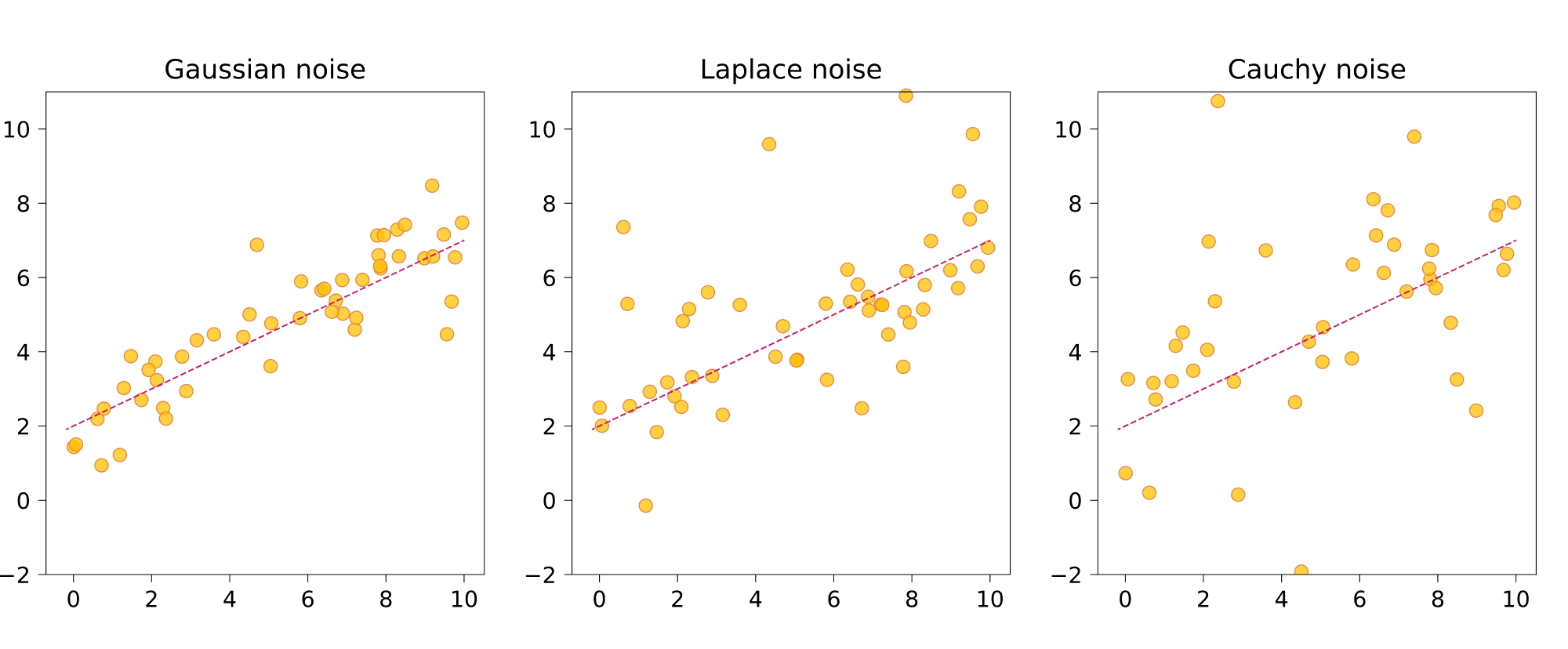
Вопрос на подумать. Зачем человеку может прийти в голову в модели линейной регрессии $y\sim Xw + \varepsilon$ предположить, что шум $\varepsilon$ имеет распределение Лапласа? А распределение Коши? Чем свойства таких моделей будут отличаться от свойств модели с нормальным шумом?
Попробуйте понять сами, прежде чем смотреть ответ.

Распределение Лапласа имеет «более тяжёлые хвосты», чем нормальное: это значит, что плотность медленнее падает с удалением от среднего. Таким образом, этому распределению могут подчиняться данные, в которых имеются выбросы. Если не гнаться за строгостью, можно сказать, что модель с нормальным шумом будет пытаться объяснить выбросы, меняя под них $w$, тогда как лапласовский шум потерпит их, не подгоняя $w$.
У распределения Коши хвосты «ещё более тяжёлые», что, в теории, даёт возможность модели с таким шумом описывать даже ещё более шумные данные.
Проиллюстрируем датасеты, сгенерированные из моделей с каждым из типов шума: нормальным, лапласовским и Коши.
Как вы могли заметить, в каждом из подходов после того, как мы зафиксировали признаки (то есть координаты $x_i$), остаётся своя степень свободы: в инженерном это выбор функции потерь, а в вероятностном – выбор распределения шума. Дальше в этом параграфе мы увидим, что на самом деле эти два подхода глубинным образом связаны между собой, причём выбор функции потерь – это в некотором смысле то же самое, что выбор распределения шума.
Условное распределение на таргет, непрерывный случай
Допустим, что мы исследуем вероятностную модель таргета с аддитивным шумом
$$y = f_w(x) + \varepsilon,$$
где $f_w$ – некоторая функция, не обязательно линейная с (неизвестными пока) параметрами $w$, а $\varepsilon$ – случайный шум с плотностью распределения $\varepsilon\sim p_{\varepsilon}(t)$. Для каждого конкретного объекта $x_i$ значение $f_w(x_i)$ является просто константой, но $y_i$ превращается в случайную величину, зависящую от $x_i$ (и ещё от $w$, на самом деле). Таким образом, можно говорить об условном распределении
$$p_y(y \vert x, w)$$
Для каждого конкретного $x_i$ и $w$ распределение соответствующего $y_i$ – это просто $p_{\varepsilon}(y - f_{w}(x_i))$, ведь $y - f_w(X) = \varepsilon$.
Пример. Рассмотрим вероятностную модель $y = \langle x, w\rangle + \varepsilon$, где $\varepsilon\sim\mathcal{N}(0, \sigma^2)$. Тогда для фиксированного $x_i$ имеем $y_i = \langle x_i, w\rangle + \varepsilon$. Поскольку $\langle x_i, w\rangle$ – константа, мы получаем
$$y_i\sim\mathcal{N}(\langle x_i, w\rangle, \sigma^2).$$
Это можно записать и так:
$$p(y_i\vert x_i, w)\sim\mathcal{N}(y_i\vert\langle x_i, w\rangle, \sigma^2),$$
где выражение справа – это значение функции плотности нормального распределения с параметрами $\langle x_i, w\rangle, \sigma^2$ в точке $y_i$. В частности, $\langle x_i, w\rangle = \mathbb{E}(y_i\vert x_i)$.
Более сложные вероятностные модели
На самом деле, мы можем для нашей задачи придумывать любую вероятностную модель $p_y(y \vert x, w)$, не обязательно вида $y = f_w(X) + \varepsilon$. Представьте, что мы хотим предсказывать точку в плоскости штанг, в которую попадает мячом бьющий по воротам футболист. Можно предположить, что она имеет нормальное распределение со средним (цель удара), которое определяется ситуацией на поле и состянием игрока, и некоторой дисперсией (т.е. скалярной ковариационной матрицей), которая тоже зависит от состояния игрока и ещё разных сложных факторов, которые мы объявим случайными. Состояние игрока – это сложное понятие, но, вероятно, мы можем выразить его, зная пульс, давление и другие физические показатели. В свою очередь, ситуацию на поле можно описать, как функцию от позиций и движений других игроков, судьи и зрителей – но всего не перечислишь, поэтому нам снова придётся привлекать случайность. Таким образом, мы получаем то, что называется графической моделью:
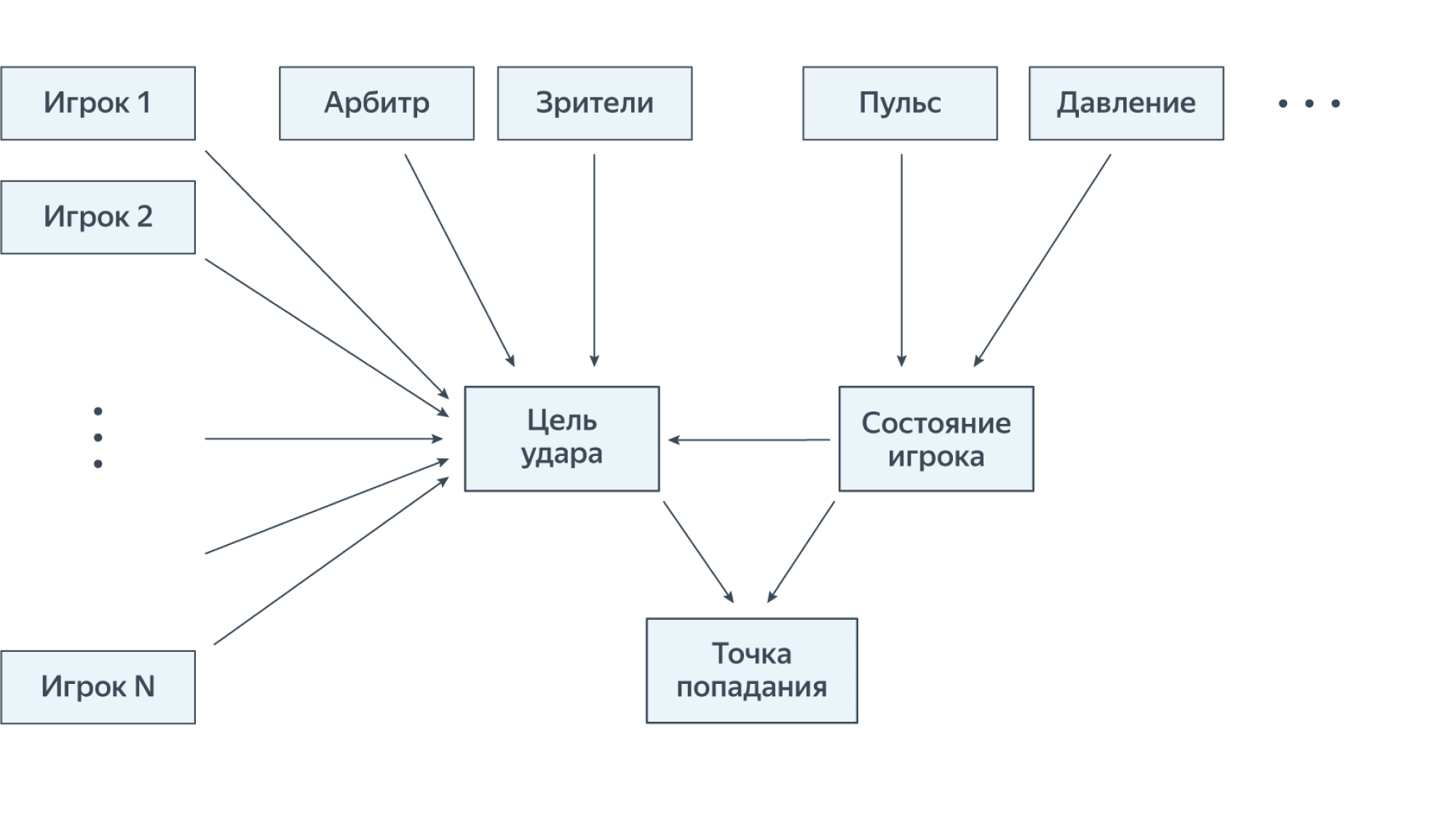
Здесь стрелки означают статистические зависимости, а отсутствие стрелок – допущение о статистической независимости. Конечно же, это лишь допущение, принятое нами для ограничения сложности модели: ведь пульс человека и давление взаимосвязаны, равно как и поведение различных игроков на поле. Но мы уже обсуждали, что каждая модель, в том числе и вероятностная, является лишь приблизительным отражением бесконечно сложного мира. Впрочем, если у нас много вычислительных ресурсов, то никто не мешает нам попробовать учесть и все пропущенные сейчас зависимости.
Расписав всё по определению условной вероятности, мы получаем следующую вероятностную модель:

в которой, конечно же, мы должны все вероятности расписать через какие-то понятные и логически обоснованные распределения – но пока воздержимся от этого.
Оценка максимального правдоподобия = оптимизация функции потерь
Мы хотим подобрать такие значения параметров $w$, для которых модель $p_y(y \vert x, w)$ была бы наиболее адекватна обучающим данным. Суть метода максимального правдоподобия (maximum likelihood estimation) состоит в том, чтобы найти такое $w$, для которого вероятность (а в данном, непрерывном, случае плотность вероятности) появления выборки $y = {y_1, \ldots, y_N}$ была бы максимальной, то есть
$$\widehat{w}_{MLE} = \underset{w}{\operatorname{argmax}}p(y \vert X, w)$$
Величина $p(y \vert X, w)$ называется функцией правдоподобия (likelihood). Если мы считаем, что все объекты независимы, то функция правдоподобия распадается в произведение:
$$p(y \vert X, w) = p(y_1 \vert x_1, w) \cdot\ldots\cdot p(y_i \vert x_i, w)$$
Теперь, поскольку перемножать сложно, а складывать легко (и ещё поскольку мы надеемся, что, раз наши объекты всё-таки наблюдаются в природе, их правдоподобие отлично от нуля), мы переходим к логарифму функции правдоподобия:
$$l(y \vert X,w) = \log{p(y_1 \vert x_1, w)} + \ldots + \log{p(y_i \vert x_i, w)}$$
эту функцию мы так или иначе максимизируем по $w$, находя оценку максимального правдоподобия $\hat{w}$.
Как мы уже обсуждали выше, $p(y_i \vert x_i, w) = p_{\varepsilon}(y - f_{w}(x_i))$, то есть
$$l(y \vert X,w) = \sum\limits_{i=1}^N\log{p_{\varepsilon}(y_i - f_w(x_i))}$$
Максимизация функции правдоподобия соответствует минимизации
$$\sum\limits_{i=1}^N\left[-\log{p_{\varepsilon}(y_i - f_w(x_i))}\right]$$
а это выражением можно интерпретировать, как функцию потерь. Вот и оказывается, что подбор параметров вероятностей модели с помощью метода максимального правдоподобия – это то же самое, что «инженерная» оптимизация функции потерь. Давайте посмотрим, как это выглядит в нескольких простых случаях.
Пример. Давайте предположим, что наш таргет связан с данными вот так:
$$y_i = \langle x_i, w \rangle + \varepsilon$$
где $\varepsilon\sim\mathcal{N}(0, \sigma^2)$, то есть
$$p(\varepsilon) = \frac{1}{\sqrt{2 \pi \sigma^2}} \exp\left(-\frac{\varepsilon^2}{2\sigma^2}\right)$$
Случайная величина $y_i$ получается из шума $\varepsilon$ сдвигом на постоянный вектор $\langle x_i, w \rangle$, так что она тоже распределена нормально с той же дисперсией $\sigma^2$ и со средним $\langle x_i, w \rangle$
$$p(y\vert x, w) = \frac{1}{\sqrt{2 \pi \sigma^2}} \exp\left(-\frac{(y - \langle x_i, w \rangle)^2}{2\sigma^2}\right)$$
Правдоподобие выборки имеет вид
Логарифм правдоподобия можно переписать в виде
$$ l(y \vert X,w) = \sum_{i=1}^N \left(-\log({\sqrt{2 \pi \sigma^2}}) -\frac{(y_i-\langle w,x_i\rangle)^2}{2\sigma^2}\right)$$
Постоянными слагаемыми можно пренебречь, и тогда оказывается, что максимизация этой величины равносильна минимизации
Мы получили обычную квадратичную функцию потерь. Итак, обучать вероятностную модель линейной регрессии с нормальным шумом – это то же самое, что учить «инженерную» модель с функцией потерь MSE.
Вопрос на подумать. Какая вероятностная модель соответствует обучению линейной регрессии с функцией потерь MAE
$$ \sum_{i=1}^N \vert y_i-\langle w,x_i\rangle\vert?$$
Попробуйте определить сами, прежде чем смотреть ответ.
$$ \sum_{i=1}^N\left[-\vert y_i-\langle w,x_i\rangle\vert\right]$$
Мы хотим найти такое распределение, для которого эта штука является с точностью до константы логарифмом функции правдоподобия. Что ж, возьмём экспоненту:
$$\text{exp}\left[-\sum_{i=1}^N\vert y_i-\langle w,x_i\rangle\vert\right] = \prod_{i=1}^N\text{exp}\left(-\vert y_i-\langle w,x_i\rangle\vert\right)$$
Если теперь это умножить на $\left(\frac12\right)^{N}$, то мы получим функцию правдоподобия для распределения Лапласа:
$$\prod_{i=1}^N\text{exp}\left(-\frac12\vert y_i-\langle w,x_i\rangle\vert\right) = \prod_{i=1}^NLaplace\left(y_i-\langle w,x_i\rangle\right)$$
Итак, учить «инженерную» модель с функцией потерь MAE – это то же самое, что обучать вероятностную модель линейной регрессии с лапласовским шумом.
Предсказание в вероятностных моделях
Теперь представим, что параметры подобраны, и подумаем о том, как же теперь делать предсказания.
Рассмотрим модель линейной регрессии
$$y = \langle x, w\rangle + \varepsilon,\quad\varepsilon\sim\mathcal{N}(0,\sigma^2)$$
Если $w$ известен, то для нового объекта $x_0$ соответствующий таргет имеет вид
$$y_0 = \langle x_0, w\rangle + \varepsilon\sim\mathcal{N}(\langle x_0, w\rangle, \sigma^2)$$
Таким образом, $y_0$ дан нам не точно, а в виде распределения (и логично: ведь мы оговорились выше, что ответы у нас искажены погрешностью, проинтерпретированной, как нормальный шум). Но что делать, если требуют назвать конкретное число? Кажется логичным выдать условное матожидание $\mathbb{E}(y_0\vert x_0) = \langle x_0, w\rangle$, тем более что оно совпадает с условной медианой и условной модой этого распределения.
Если же медиана, мода и математическое ожидание различаются, то можно выбрать что-то из них с учётом особенностей задачи. Но на практике в схеме $y\sim f(x) + \varepsilon$ чаще всего рассматривают именно симметричные распределения с нулевым матожиданием, потому что для них $f(x)$ совпадает с условным матожиданием $\mathbb{E}(y\vert x)$ и является логичным точечным предсказанием.
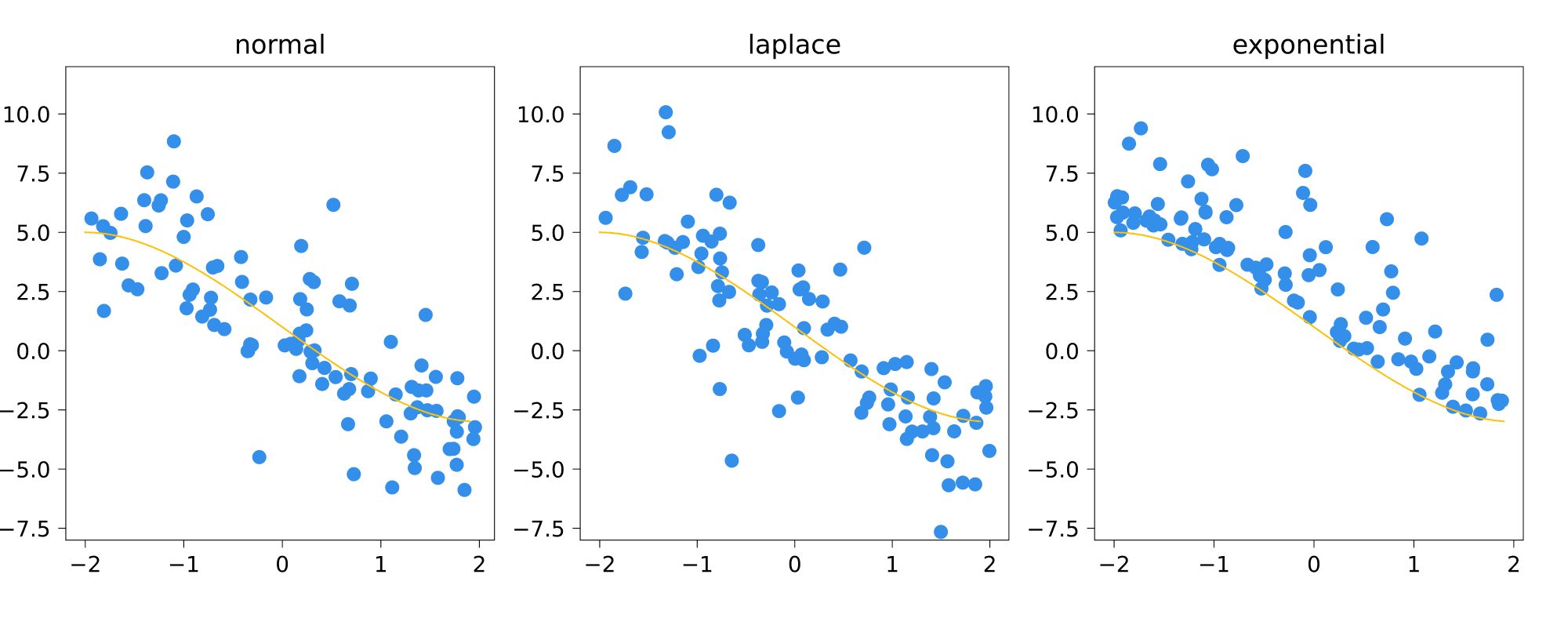
Приведём пример. Допустим шум $\varepsilon$ был бы из экспоненциального распределения. Тогда $f(x)$ была бы условным минимумом распределения. В принципе, можно придумать задачу, для которой такая постановка (предсказание минимума) была бы логичной. Но это всё же довольно экзотическая ситуация. Приводим для сравнения модели с нормальным, лапласовским и экспоненциальным шумом:
Условное распределение на таргет, дискретный случай
Допустим, мы имеем дело с задачей классификации с $K$ классами. Как мы можем её решать? Самый наивный вариант – научиться по каждому объекту $x_i$ предсказывать некоторое число для каждого класса, и у кого число больше – тот класс и выбираем! Наверное, так можно сделать, если мы придумаем хорошую функцию потерь. Но сразу в голову приходит мысль: почему бы не начать предсказывать не просто число, а вероятность?
Таким образом, задача классификации сводится к предсказанию
$$P(y_i = k \vert x_i)$$
и как будто бы выбору класса с наибольшей вероятностью (как мы увидим дальше, всё не всегда работает так просто).
Одну такую модель – правда, только для бинарной классификации – вы уже знаете. Это логистическая регрессия:
$$P(y_i = 1 \vert x_i,w) = \frac{1}{1+e^{-\langle x_i, w\rangle}},\quad P(y_i = 0 \vert x_i,w) = \frac{e^{-(x_i, w)}}{1+e^{-\langle x_i, w\rangle}} = \frac{1}{1+e^{\langle x_i, w\rangle}}$$
которую также можно записать в виде
$$y_i \vert x_i \sim \color{red}{Bern}\left(\frac{1}{1+e^{-\langle x_i, w\rangle}}\right)$$ где $\color{red}{Bern}(p)$ – распределение Бернулли с параметром $p$.
Нахождение вероятностей классов можно разделить на два этапа:
где, напомним, $\sigma$ – это сигмоида:
$$\sigma(t) = \frac{1}{1+e^{-t}}$$
Сигмоида тут не просто так. Она обладает теми счастливыми свойствами, что
монотонно возрастает;
отображает всю числовую прямую на интервал $(0,1)$;
$\sigma(-x) = 1 - \sigma(x)$.
Вот такой вид имеет её график:
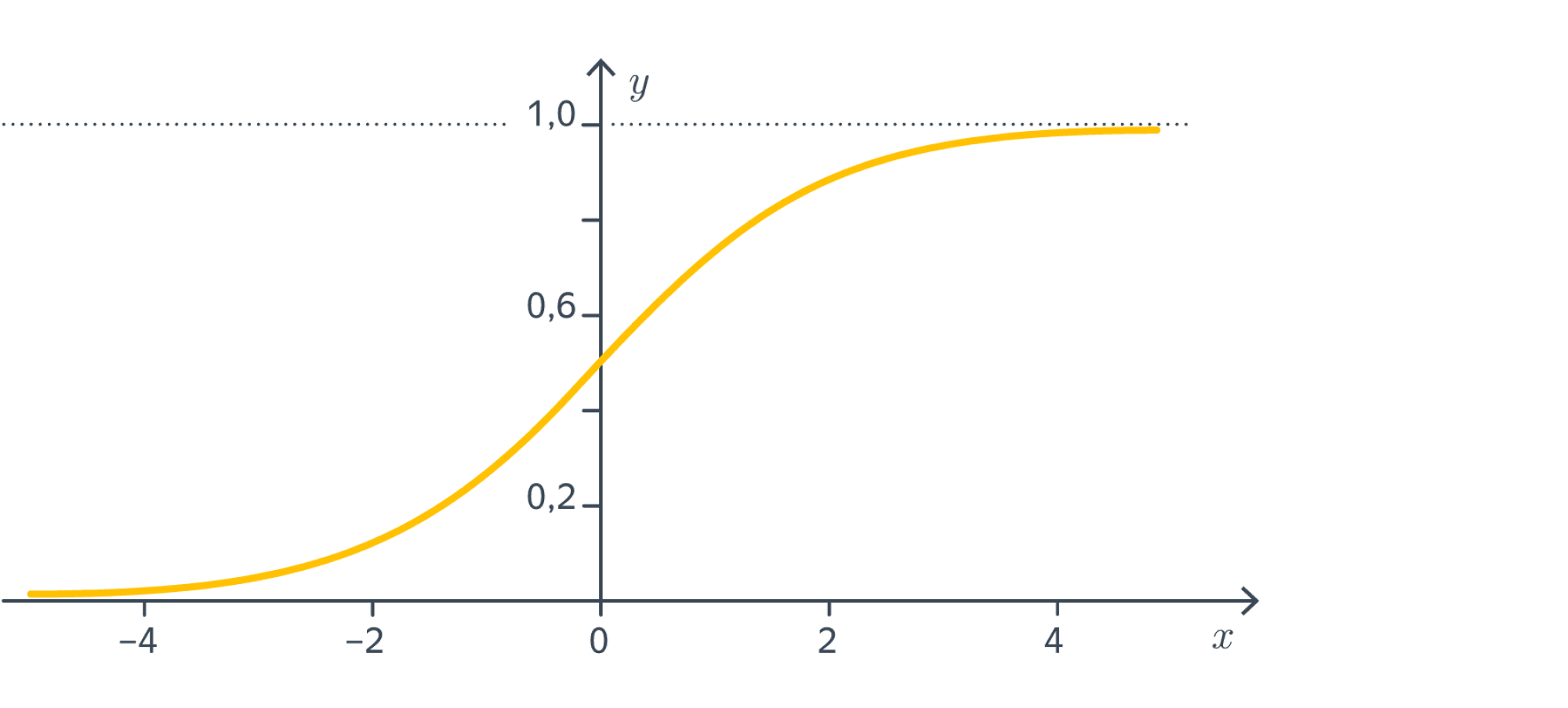
Иными словами, с помощью сигмоиды можно делать «вероятности» из чего угодно, то есть более или менее для любого отображения $f_w$ (из признакового пространства в $\mathbb{R}$) с параметрами $w$ построить модель бинарной классификации:
$$P(y_i = 0 \vert x_i, w) = \sigma(f_w(-x_i)),\quad P(y_i = 1 \vert x_i, w) = \sigma(f_w(x_i)).$$
Как и в случае логистической регрессии, такая модель равносильна утверждению о том, что
$$f_w(x_i) = \log{\frac{p(y = 1 \vert x_i,w)}{p(y = 0 \vert x_i, w)}}.$$
Похожим способом можно строить и модели для многоклассовой классификации; в этом нам поможет обобщение сигмоиды, которое называется softmax:
$$softmax(t_1,\ldots,t_K) = \left(\frac{e^{t_1}}{\sum_{k=1}^Ke^{t_k}},\ldots,\frac{e^{t_K}}{\sum_{k=1}^Ke^{t_k}}\right)$$
А именно, для любого отображения $f_w$ из пространства признаков в $\mathbb{R}^K$ мы можем взять модель
$$\left(P(y_i = k \vert x_i, w)\right)^K_{k=1} = softmax(f_w(x_i))$$
Если все наши признаки – вещественные числа, а $f_w(x_i) = x_iW$ – просто линейное отображение, то мы получаем однослойную нейронную сеть
$$\left(P(y_i = k \vert x_i, w)\right)^K_{k=1} = softmax(x_iW)$$
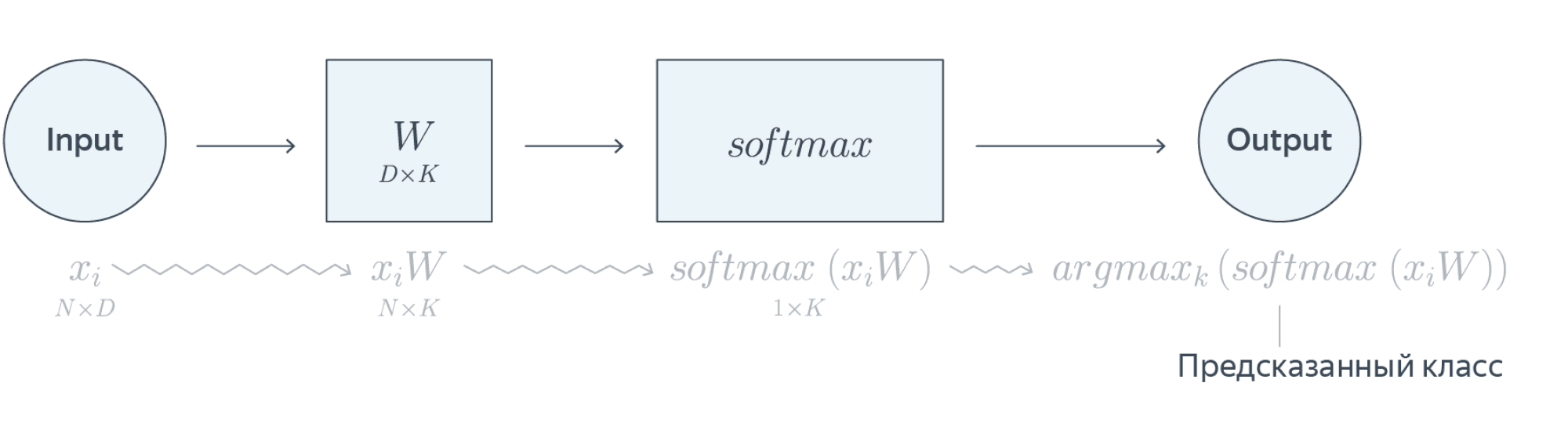
Предостережение. Всё то, что мы описали выше, вполне работает на практике (собственно, классификационные нейросети зачастую так и устроены), но корректным не является. В самом деле, мы говорим, что строим оценки вероятностей $P(y_i = k \vert x_i, w)$, но для подбора параметров используем не эмпирические вероятности, а только лишь значения $\underset{k}{\operatorname{argmax}} \ P(y_i = k \vert x_i, w)$, то есть метки предсказываемых классов. Таким образом, при обучении мы не будем различать следующие две ситуации:
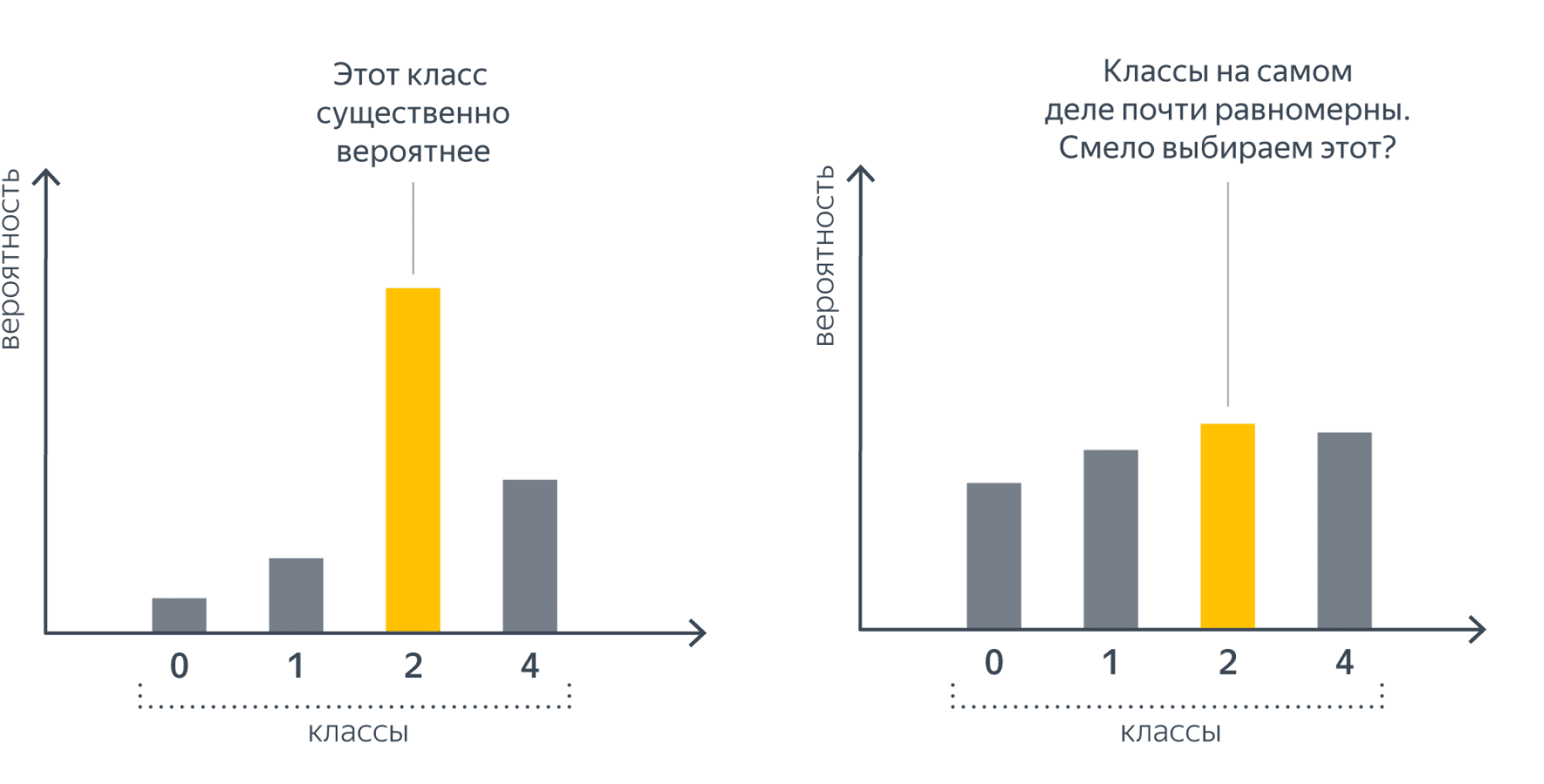
Это говорит нам о некоторой неполноценности такого подхода.
Заметим ещё вот что. В случае бинарной классификации выбор предсказываемого класса как $\underset{k}{\operatorname{argmax}} P(y_i=k \vert x_i,w)$ равносилен выбору того класса, для которого $P(y_i=k \vert x_i,w) > \frac{1}{2}$. Но если наши оценки вероятностей неадекватны, то этот вариант проваливается, и мы встаём перед проблемой выбора порога: каким должно быть значение $\widehat{t}$, чтобы мы могли приписать класс 1 тем объектам $x_i$, для которых $\sigma(f_w(x_i)) > \widehat{t}$?
В одном из следующих разделов текущего параграфа мы обсудим, как всё-таки правильно предсказывать вероятности.